
Whether you’re assembling data for display on a report, gathering up primary keys from a found set of records, or looping through a record set to perform some type of data operation, creating a list of values is a frequent key step in many algorithms.
When we’re working with complex data structures, JSON is our go to format, but there are times when we just need a carriage return separated list. In this post, we look at some of the methods that we have used over the years to generate this type of list. Depending on our requirements, some list creation methods are better than others, and we present here a guide for making good decisions when creating a list of values.
Deciding Factors
Some methods work well with a found set of records, while others require an embedded query. Some work well with very large data sets, and others are only useful with a small record count. The nature of the data might also be important; whether we are tracking a single value or multiple values, text or numeric data, or whether there’s the possibility of carriage returns in our data might make a difference in our choice of methods. For the purposes of this post, we’re keeping it simple; we investigate here several algorithmic approaches to assembling a list of carriage return separated primary keys (UUID’s).
The Task
Let’s look at a simple example; let’s say we’ve got a set of records and we want to assemble a list of the primary keys.

From this set of records, we want to produce the following list:
04708FE0-C838-4423-8A3D-AB48BC9CAA4C
1C50581F-E7C0-4D2C-8C47-F3F5802F01EF
EA120025-F905-41AE-AAA5-BB14B4E88A88
6F1ACD89-D259-4695-803D-9D9DC3128F35
853C3F3D-E020-4794-9180-892CEC1CA3FA
967B324F-543E-472F-BEAE-DBA932EF2E32
5239AB2E-6AD0-40A0-B8E7-EF26F62BD6DE
40B345CD-D91B-49C7-AEE1-9916F168E5C4
DED4591A-8F4E-4693-B15B-B8DFE2845AAA
4301E0DD-97D1-4511-92D1-75F6E4317DD4
Looping Through Records
One of the simplest methods to generate this list of ID’s is to loop though the found set of records and append the value of the ID to a variable.
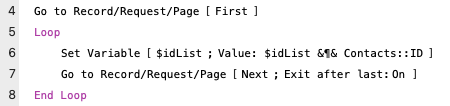
Looping through the found set
This method can be quite quick for smaller record sets, but suffers from the fact that (as written) it may leave you on a different record than the one you started on. There are of course methods to avoid this problem, (the most common is to use a New Window script step and perform the ID gathering in a throwaway window), but that’s a topic for another post. Of course, we may also need to deal with the leading carriage return in our list that this method will generate (the method above will generate a list of the form “¶ID1¶ID2¶ID3…” and not “ID1¶ID2¶ID3…”).
When you’re working with related data, you might modify this method slightly to step through portal rows rather than records. “Go to Record []” becomes “Go to Portal Row” [], and the “Set Variable []” step would need to reference the ID in the related table, but otherwise the script is identical.
Of note, storing and managing the contents of the ever growing variable in memory seems to impart a performance penalty (with exponential growth) over writing the value to a file. Take a look at the script “Looping List (stream to file)” for an alternate approach that performs dramatically better as the found set of records gets very large. Writing to a file will get slower as the record count gets larger, but in our limited testing, this performance penalty seems to grow linearly as the found count goes up.
Get Nth Record
Using the Get Nth Record FileMaker function can easily generate the same ID list as above but avoids the problem of potentially getting left on a different record. The script looks almost identical, we just don’t need to go to each record, we can stay right where we started in the found set.
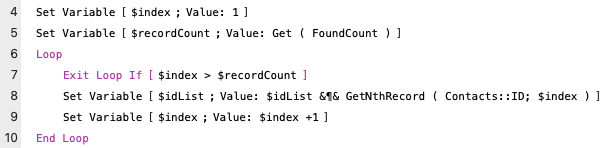
This method also works quite well on related data, you don’t even need a portal like you do with the looping through portal method.
Summary List Of
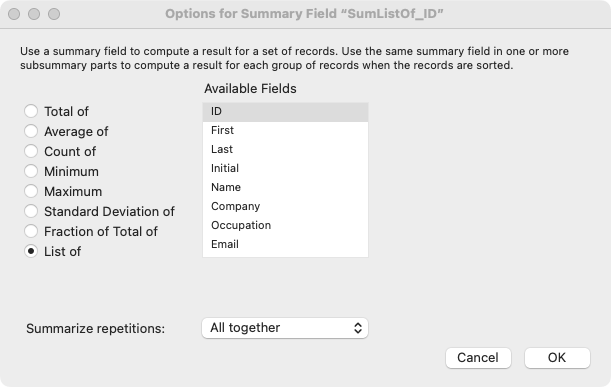
One of our favorite methods for generating a simple list of ID’s is to use a summary field. If you add a Summary field to your table that uses the List Of method and points to your primary key, you can leverage this field to very quickly generate a carriage return delimited list of ID’s for your found set or for a set of related records.


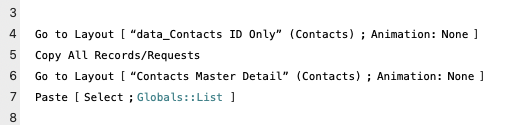
Copy All Records
The copy all records technique has been a staple for FileMaker developers for decades, though it has waned in popularity in favor of more modern techniques. Essentially, we use the copy all records script step on a special layout that has only the fields that we’re interested in. If that layout has only our ID field, we get a return separated list of keys from the found set of records on our clipboard. We can paste this result into a field and the task is complete.

Global Replace
This method uses a Replace Field Contents operation, but rather than a standard text, timestamp, number, or date field, it uses a global field as the target. Apparently since the Replace Field Contents operation is inherently cycling through all the records in the found set, with an appropriate calculation, we can use this operation to concatenate all results in a carriage return separated list.

Since we’re using the List() function, we get a nicely formatted list with no leading (or trailing) carriage returns.
Execute SQL
Execute SQL can be an excellent way to produce a list, especially since the default record separator is a carriage return. While it’s not trivial to capture a found set of records with Execute SQL, if your process is already needing to perform some type of find or query, using an SQL statement can be super useful. While this example query isn’t particularly interesting (we’re just limiting the number of records returned with $queryCount), the statement is straightforward. We expect a carriage return delimited list of ID’s.
Execute Data API
The last technique that we’ll cover also doesn’t operate on the found set of records, and we’ll need to specify a query as part of our request. With Execute Data API [] we will also need a special layout that includes the field(s) for the data we’d like to return.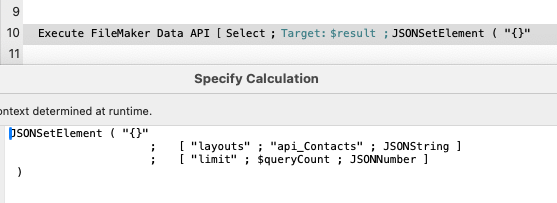
The Execute FileMaker Data API [] script step uses a JSON object to specify our request. In this case, we’re pointing to the api_Contacts layout, and limiting our results to the first $queryCount records. Although the specified layout has only one field on it (our ID), we don’t get just a simple return delimited list; the Execute Data API script step returns a JSON object that contains quite a bit more information than we actually need, and we’ll need to parse this JSON further if our goal is a simple list.
Here’s the result with for a set of three records: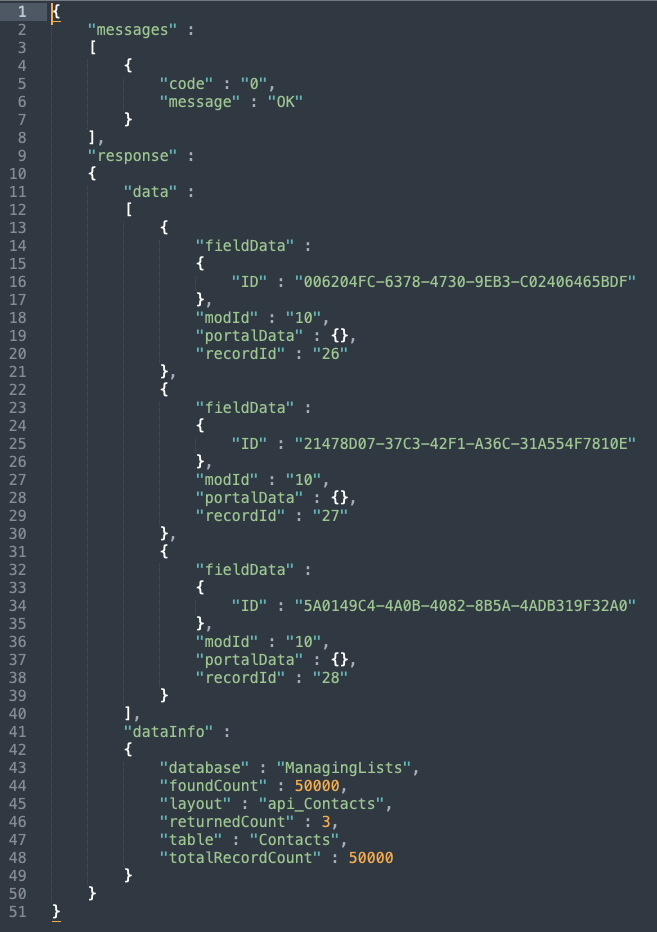
What we’re really after is the array of data at response.data.fieldData.ID. We can use any number of techniques to pull this ID from the JSON object but our favorite at Codence is often the JSONQuery custom function. That said, if our intention is to produce a return separated list of IDs, this technique should probably be discarded as an option since we’re really just creating more work for ourselves with this two step process. If the Execute Data API and JSONQuery combination were somehow super fast or had other redeeming features, we might change our mind.
Choosing A Method
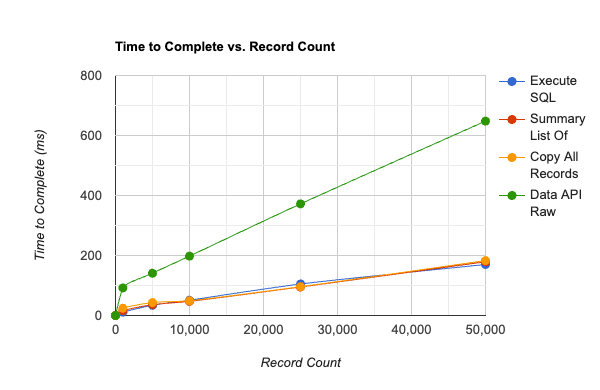
Choosing one method over another is often a matter of what we have on hand when we need a list. How much scaffolding do we need to create to be able to get our list, (do we need to create a field or a layout)? Further, some methods are faster than others. In our testing, we found that all of these methods are reasonably quick, even with a set of 1,000 records, but as the record count goes up, some of these methods get unreasonably slow.
In short, the global replace method (not charted) is the slowest with times on the order of 30-40 times slower than the next fastest methods. The get Nth record and looping list methods are the next poorest performers with what appears to be exponentially increasing times as the record count goes up. Execute SQL, summary list of, and copy all records are the best performers with linearly increasing times as record count goes up (at least over the span of the data sets tested).

Tailoring List Creation Techniques to Your Data Needs
If your data set is small (a few dozen records, or even a few thousand) any of the methods mentioned here should work nicely to produce a set of return delimited values. If your application needs to support 10’s of thousands or more records, then execute SQL and summary list of should be your go to methods. Even though it’s quite performant, we tend to shy away from the copy all records method only because it messes with the user clipboard and could produce unexpected behavior when pasting.
What are your favorite methods? Drop us a line and let us know.

Built with you in mind
Speak to one of our expert consultants about making sense of your data today. During
this free consultation, we'll address your questions, learn more about your business, and
make some immediate recommendations.